
Datadog Releases ARFBench, an AI Benchmark Built on Real Incidents

System failures cost more than a trillion dollars annually. When outages strike, engineers race to analyze observability metrics, time series data that captures the health of software systems. Now, Datadog wants AI to help. The company has introduced the Anomaly Reasoning Framework Benchmark (ARFBench), an open-source ARFBench AI time series benchmark built from real Datadog internal incidents.
The benchmark targets time series question-answering (TSQA) tasks, specifically the kind engineers perform during incident response. Examples include identifying when latency started increasing or determining which metrics are behaving abnormally. These are also the tasks that SRE models and agents must perform well to be genuinely useful.
ARFBench consists of 750 question-answer pairs drawn from 142 time series and 63 real incidents. Questions are organized in three tiers of increasing difficulty, where higher-tier tasks depend on correct reasoning at lower tiers. Unlike many synthetic benchmarks, ARFBench uses real production data and enriches each example with expert annotations and additional context (Figure 1).
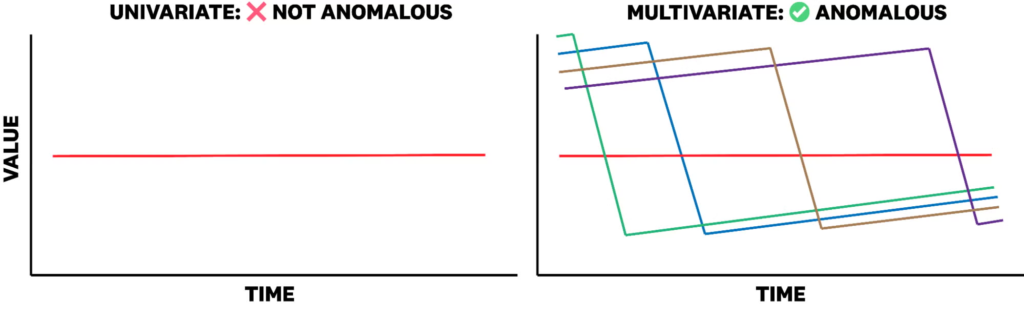
Figure 1: When analyzed alone, variates of a time series may not be anomalous. However, in the context of a grouping of variates, the same variate may be considered anomalous. The multivariate time series in this figure is based on the average remaining TLS certificate lifetime across different clusters and IDs of a particular service.
In benchmarking tests, the top-performing model was GPT-5, reaching 62.7% accuracy. However, it still fell short of domain experts. Datadog also tested a new hybrid model, Toto-1.0-QA-Experimental, combining its own open-weights time series foundation model Toto with Qwen3-VL-32B. This hybrid reached 63.9% accuracy and outperformed all models on anomaly identification by at least 8.8 percentage points in F1 (Figure 2).
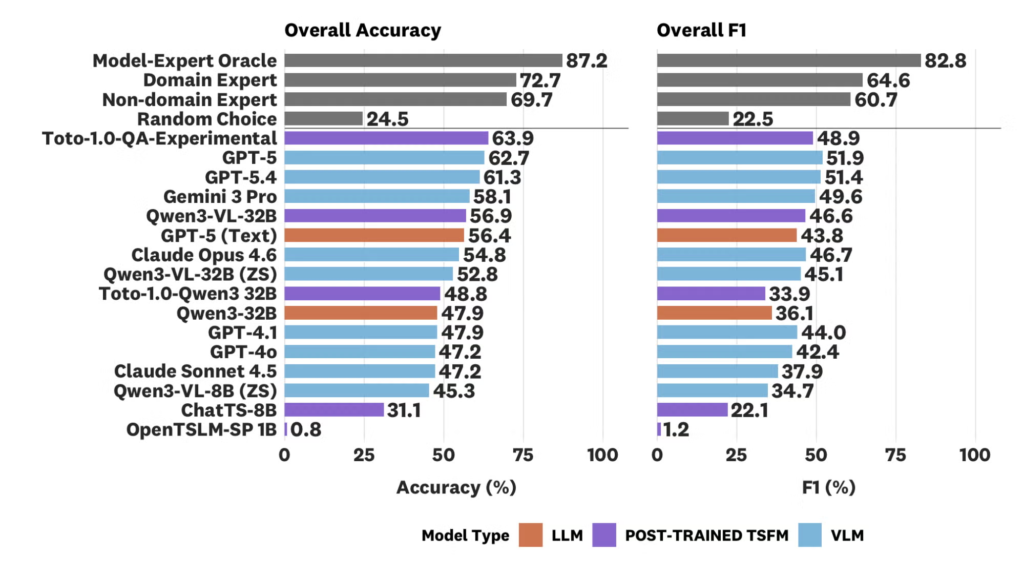
Figure 2: Overall accuracy and F1 of various baselines and foundation models on ARFBench. Models are sorted by decreasing accuracy. The Toto-1.0-QA-Experimental achieves the top accuracy on ARFBench and yields comparable F1 to top frontier models.
Notably, the error profiles of models and human experts were markedly different. Models failed where experts succeeded, and vice versa. This complementary behavior sets the stage for a model-expert oracle reaching 87.2% accuracy, a new superhuman frontier for the field.
The ARFBench AI time series benchmark, leaderboard, and model weights are available on Hugging Face, and evaluation code is on GitHub






