
AI Memory Semiconductors Future: SK hynix Makes Its Case

The AI memory semiconductors future is not simply about speed. It is about whether memory can think. That is the core argument SK hynix makes in the debut of its Tech Note series, published May 12.
AI has a memory problem. And solving it could reshape the entire semiconductor industry.
Today’s large language models, ChatGPT, Gemini, Claude, suffer from a structural flaw. They recall everything from training, but they cannot form new long-term memories afterward. To compensate, tech companies burn through vast quantities of GPUs and HBM. They force models to re-read entire conversation histories with every new query. That cycle is expensive. Moreover, it is fast becoming unsustainable.
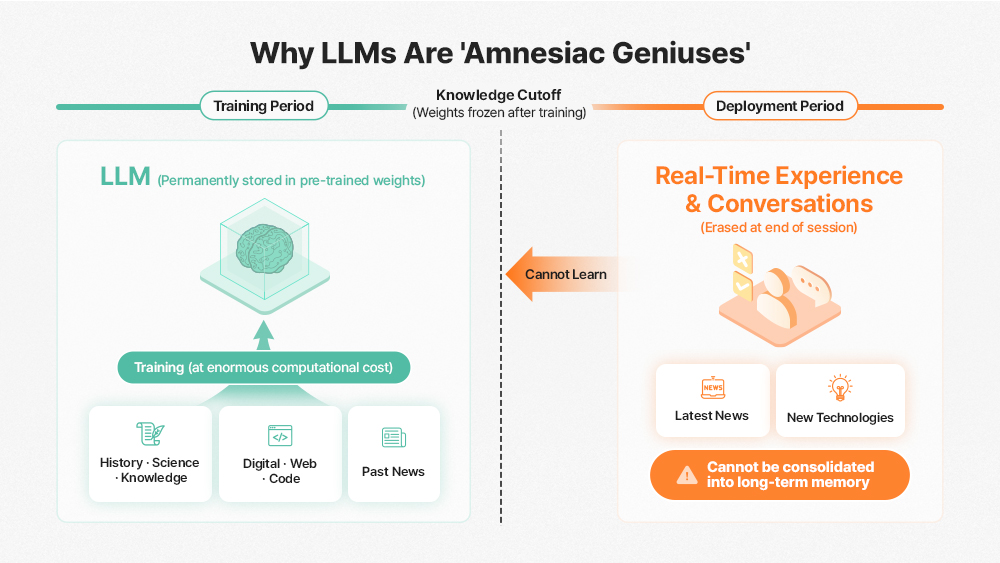
The structural limitation that prevents LLMs from running new information and knowledge in real-time
Kim Juchan, a semiconductor device researcher at KAIST, argues the shift is already underway. Starting in 2026, Google’s Continual Learning framework and the Titans Architecture are expected to trigger the collapse of Static Inference. Rather than training once and freezing model weights, training and inference will merge. Inference itself will perform fine-grained weight updates to enable continuous post-deployment learning.
That architectural shift matters enormously for hardware. Existing memory semiconductors, DRAM and HBM, were designed around a read-heavy access pattern. However, with Continual Learning in the pipeline, memory must now handle frequent Read-Modify-Write operations. Simply scaling bandwidth cannot absorb that surge.
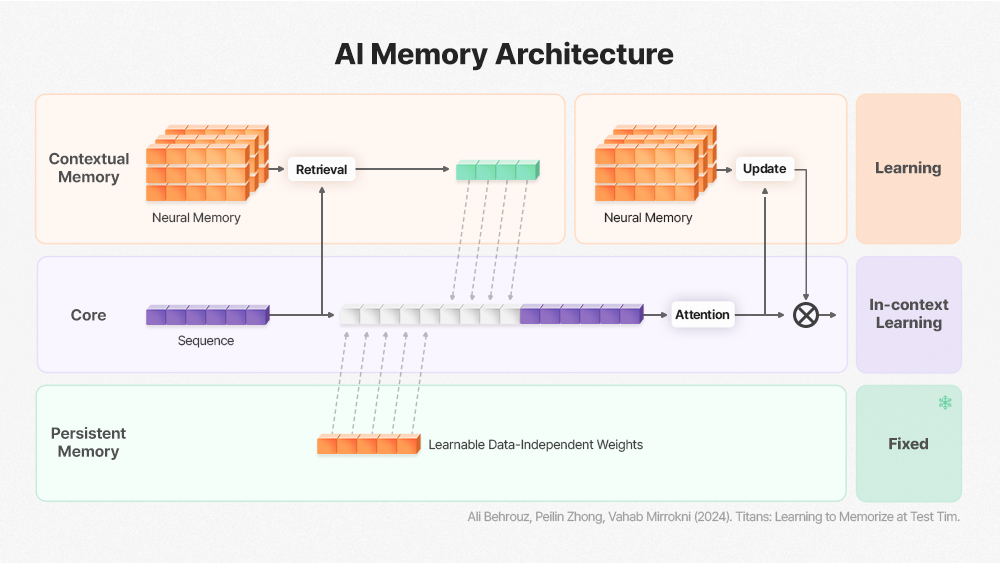
AI Memory Architecture as introduces in Google’s Titans Paper
The answer, researchers argue, is computation inside the memory itself. A PIM-based architecture such as GDDR6-AiM reduces the GPU-to-memory bottleneck by processing traffic directly within the memory die. As a result, round-trip latency disappears. A genuinely real-time learning pipeline becomes possible.
A separate challenge is also emerging: memory predictability. Taekyoon Park, a researcher at Siemens, notes that systems with theoretically sufficient memory specs still fall short in real-world production. Even HBM-equipped systems suffer repeated latency spikes under specific workloads. The root cause is rarely a bandwidth shortfall. Instead, it stems from a mismatch between average throughput and the deterministic response that live service environments demand.
Consequently, the industry is converging on a new priority. Tail latency, not average bandwidth, now governs system reliability. Latency-centric memory, therefore, will increasingly decide competitive outcomes.
The transformation extends beyond training and inference. It reaches telecommunications. The defining innovation of 6G is not simply higher speed. Rather, it is the delegation of network control to AI. AI-RAN will enable base stations to optimize spectrum allocation and data routing in real time. Furthermore, with roughly 12 million base stations deployed globally, embedding AI accelerators into cellular infrastructure opens an entirely new market at scale.
Against this backdrop, SK hynix’s planned $400 billion investment in the Yongin Semiconductor Cluster carries strategic logic. This is not a routine capital expansion. It is a direct response to a structural shift in the AI memory semiconductors future. Additionally, the company’s P&T packaging and test facility under construction in Cheongju, South Korea, is expected to draw roughly $13 billion on its own.
SK hynix has also initiated R&D into High Bandwidth Flash, an emerging memory tier bridging HBM and SSD. That move signals the company is not content to rest on its current HBM lead.
The current AI investment cycle may yet correct. But the broader transition, toward AI systems that learn, retain, and evolve, looks irreversible. Memory semiconductor technology remains the indispensable foundation. Ultimately, how the global memory industry meets these demands will define one of the most consequential technology stories of this decade.






